Table of Contents
- When does prototyping end and simulation begin?
- Where is the harm?
- A liberating development cycle picture
- Literate modeling introduced
- I’ll take a blog for starters
- Reflection
- Footnotes
I’m really interested to revisit Andrew Davison’s Sumatra project, and especially the web server version, as part of my research into literate modeling, which overlaps with simulation management in several ways. Sumatra is one of the only usable, functioning projects that I’ve come across that really tackle the reproducibility needs of computational scientists.
Daniel Wheeler, a developer who uses Sumatra and has forked it in order to break up the stack into smaller modules and improve its rate of community adoption, wrote a good blog article last year about the future of the package.
There is an enormous amount of focus in computational science on simulation when it’s not (now) talking about data. This sounds great, but there’s comparatively little talk in the computational community about the applied math (and I don’t mean statistics) that goes into the creation of the predictive model that’s simulated in the first place. Worse, we talk less and less about using models to generate theory, rather than being a scientific endpoint in themselves (which they are absolutely not). But I will have to come back to this in a later post.
When does prototyping end and simulation begin?
I want to piggyback on the comments that Daniel made about a coming revolution in scientific data management and the approach to take, because I agree with almost all of them. Daniel posted a diagram (see below) about the development cycle of reproducible research, which was intended to simplify his argument for needing simulation management software tools. His focus is on the ‘simulation’ stage, and he suggested that capturing the provenance of the ‘prototype’ and ‘develop’ stages would be difficult but also unnecessary. We certainly do need to track the simulation stage.
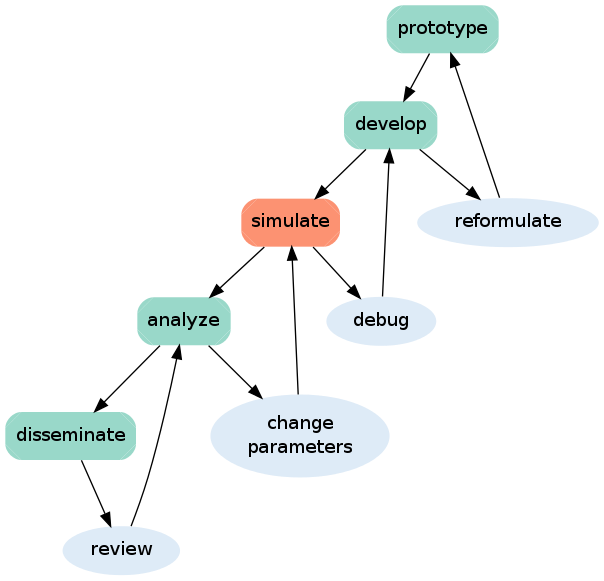
However, there is no simple demarcation between the development and simulation stages. Daniel already acknowledged this in his post’s comments, but his diagram is still a useful depiction of what I perceive to be a widespread attitude. In fact, I will argue that it’s an (April) fool’s errand to make that demarcation if we want to really get inside the guts of scientific research.
Although a seemingly innocuous and convenient abstraction, the assumption of a ‘stage’ switch between making the model and simulating it carries baggage that will be harmful to providing effective informatic support of the development cycle. While his is a straw man in this instance, I think that many computational scientists act as if that is exactly how it works, even if they’d ultimately admit that the distinctions are artificial or over-emphasized1. Well, fair enough, but once you’re even implicitly following an idealized mental model, it’s already too late to envision making progress in informatics for scientific modeling. Let’s not be that straw man….
Where is the harm?
An executable model already embodies so much provenance about the core assumptions and representational choices behind its content and formal description. That’s why, to me, it’s like “bolting the stable door after the horse has bolted” to focus only on capturing the provenance of the simulations. That’s probably too strong an analogy, especially for simulation pipelines of well-established models in well-established predictive processes. But I care much more about cutting edge science where we still have huge problems understanding what’s going on. That situation occurs anywhere where highly complex dynamic systems are in play, e.g. in multi-scale theories of cognition and other biological modeling domains.
If you wait until the model has already been developed before keeping track of its development, you’ve already lost record of the interesting and important thought process and conversation that generated the model’s content. Furthermore, if continually integrated testing (testing is presumably part of Daniel’s ‘analysis’ stage) is not explicitly inherent in all stages of the cycle then the positive impact of testing on initial model development is also lost. In particular, it is hidden from the post hoc view of the recorded provenance data. This is why my vision for computational research should involve similar informatic workflows that test-driven development does in computer science.
A liberating development cycle picture
I personally prefer an “Agile”-like model of the modeling process than the sort of “waterfall”-like model Daniel presented.
The Agile view of software development was liberating for new generations of software engineers used to a more socially interactive world enabled by open source tools. Agile-for-modeling, let’s call it, has a similar motivation. It is much less idealistic about the linear-except-a-few-feedback-tweaks kind of cycle in the diagram above. In practical terms, a mathematical model, like a theory, should never be “finished” (i.e., ready only to be simulated from hereon, or at least until after the ‘dissemination’ stage happens) and, according to the best practices of the scientific method, should never be isolated from hypothesis testing.
As with a software product, my experience with practical model development is closer to a series of “sprints” that solve urgent needs in functionality, and result in iterations of a product that works to a quantifiable degree at that point in time. Further testing, field use, and personal reflection may yield new needs (e.g. bugs or feature requests) that lead to new initiatives to change, and hopefully improve, the model.
In this new perspective, not only is there no clear demarcation between development of prototypes and simulations, but there is absolutely no demarcation at all. While I agree that, in cognitive terms, keeping track of simulation runs and its underlying code is easier to comprehend as a software engineering problem, scientifically speaking its separation from prototype exploration, learning, and testing, is harmful. The practicality of a possible solution should not be the reason that we dismiss the existence of the problem in the first place.
Literate modeling introduced
At this point, you might think my idea is worthy, but the implementation still presents the big challenge. How do we possibly capture the provenance of model prototyping and development? Well, that’s where the CS concepts of literate programming and metamodeling come into play. Yes, computer scientists have essentially already solved that problem for software development. My next post will explain this connection further. Briefly, though, the literate programming idea is to change how we work through the cycle of software development. Originally, Knuth imagined this by simply embedding explanatory documentation (text metadata) in the source code. This led to the idea of an “active document”, a human-readable text that is also executable. Similar to what an ipython notebook achieves. And that is a wonderful thing.
In literate modeling, the markup represents the hypotheses, data, mathematics, and computational models. The more sophisticated you imagine this markup, the more you can imagine converting plain text versions of these representations into verifiable definitions of executable objects. At least, representing them formally in text markup and code allows them to be manipulated, communicated, and version controlled. Of course, that step also has a high investment cost. Even without further details, if you can imagine what kind of workflow that might look like, then you can imagine that many scientistis would see that as impossibly burdensome.
I’ll take a blog for starters
Before we explore what cool, sophisticated things literate modeling could involve, let’s realize that any additional metadata created about a modeling process, and which is then version controlled, is a form of literate modeling. That could be as simple as a lab “blog” (digital notebook) that lab members can follow about the writer’s goals, process, results, etc. We could redefine “dissemination” in the diagram to refer to a social and cognitive step of digital sharing and discussion at the end of a mini-cycle.
Reflection
So, a more generous re-interpretation of the diagram I re-posted here is to slightly redefine some of the terms and possibly their originally intended meanings. The major redefinition is that this cycle should not occur at the level of the whole project lifetime, but as a micro-cycle over the course of between a day and a month. Now, “analysis” would mean data-driven testing, and “dissemination” involves a record and discussion of the current state of the model, including its assumptions and tests, with colleagues at whatever scale.
Provided the expectation is that you will continually iterate this cycle on a short-term basis, and be ready to go multiple steps back up the chain as needed, I could get behind this diagram.
Footnotes
-
I think we avoid a more complex picture of the cycle because we fear over-complicating the essential, and idealized flow of progress through the process. ↩